Scratching a Tiny Itch in Tiny Steps - A Python Side Project
How to build something tiny and useful with Python and Flask.

Every week I send a new issue of my newsletter This Week's Worth, and every week I commit to the boring effort of estimating the read times of each article I share with it. My subscribers are all saints and they deserve to know if they are clicking on a link that will take them 31 minutes to read.
When I say boring I really mean it. This was the recipe I followed every single time:
- Open the article.
- Copy the article.
- Open Read-O-Meter and paste the article.
- Get an estimate.
- Be unsatisfied with a fixed reading speed of 200 wpm.
- Divide the total number of words by 220.
And I'm not even considering the times where opening the article a second time would trigger a paywall.
What I wanted was to provide a URL to an article and get a number of minutes in return. And that seemed like the perfect-sized challenge for a side project, where, once again, Python should come to the rescue.
SPOILER ALERT: The final result.
Breaking a project in milestones
I want a web application where everyone could provide their links and receive an estimated reading time. I want to be able to configure a Word-Per-Minute speed. I want it easy to use and minimalist. I want it to be fast. All of these are great goals to have for the last iteration of this project. Not the first.
I plan to build this project in tiny steps.
- A python script that returns the article text from a given URL.
- A python script that returns the reading time of a given URL.
- Previous step + accepts a URL and wpm speed as parameters.
- An API that returns the reading time of a given URL.
- Previous step + accepts a URL and wpm speed as parameters.
- A web application that estimates the reading time of a given URL.
- Previous step + what could pass as "nice UI".
- Previous step + tiny improvements.
Defining these bite-sized milestones from the get-go provide at least two considerable advantages (if you discount the futurology and stay agile):
- Added motivation by completing goals with higher frequency;
- Higher clarity on the immediate objective and what lies ahead;
Step 1: How to get an article out of a URL
I wanted this as the first step for two main reasons: warm-up and separate functionality. I knew counting words in a body of text would be easy, but since my web scrapping experience was limited, extracting the words out of the HTML would require some investigation and would be a nice warm-up exercise coming back to Python. The other reason is related to what I could do with the end result. I would use it for this project, but it could also live on its own, for the next time I would need to extract the body of articles.
And just like that, the first line I wrote for this project was not Python in a text editor, but "python extract article from html" on Google.
What I discovered was this very nice Python library called Newspaper3k, which in six, very short, lines of code would give me the complete text of any article.
from newspaper import Article
URL = 'https://filipesilva.me/blog/when-to-use-the-java-this-keyword/'
article = Article(URL)
article.download()
article.parse()
print(article.text)That's it. Even if you are not familiar with Python syntax I think it's pretty self-explanatory what each line does.
Step 2: How to get the read time of an article
In this step, I have to count the words in the article text and then just apply simple math. We can get the number of the words of an article with these two lines:
words = article.text.split()But there's a problem. We are splitting the text by whitespaces and if some punctuation appears isolated, like for example in lines of code, we would get symbols counted as words.
To solve this small issue I reverted, for now, to extracting the words with a regular expression which, instead of excluding the characters I don't want, it only gets me words with the ones I need. You know them: numbers, letters, dashes, underscores, and apostrophes.
words = re.findall("[0-9a-zA-Z_'-]+", article.text)Then, it's just dividing the number of words by a given Words-Per-Minute constant (I use 220). Also decided to round down the estimation because on the Internet everyone skims.
word_count = len(words)
estimated_read_time = math.floor(word_count / WPM)I could end this here and it would already help on the newsletter writing process. But...
Step 3: How to pass arguments to Python script
I see three levels in this step. In order of importance:
- I want the script to accept one URL.
- I want the script to accept one URL and one WPM number.
- I want the script to accept a list of URLs.
Here, after a brief research, I discovered the argparse Python module which promised easy implementation of Command-Line Interfaces. It delivered.
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--url", help="Define URL for the article to estimate read time.", required=True)
args = parser.parse_args()
article = Article(args.url)In five lines I was able to set up the beginning of, what could be, a read-time-estimating CLI. I can define the name of the URL argument (as "url"), offer a brief description of what it means, and even mark it as required for the estimation to work.
Now, for each new argument, and in this particular case Words-Per-Minute, I just need to add another line like this:
parser.add_argument("--wpm", help="Define the words-per-minute speed.")This is not required for our little program to work, because we will always have a default value to estimate with.
Lastly, we need to be able to pass as many URLs as we want. The solution comes in the form of a parameter, appropriately, named 'nargs'. We need to pass to it an '*' to group all URLs we may throw at it into a list, so that we can then iterate through them and apply our estimation algorithm.
parser.add_argument("--url", nargs='*', required=True, help="Define URLs for the articles to estimate read time.")
args = parser.parse_args()
for url in args.url:
# call estimate read time function
This is the end of step 3 of the 'script-only' part of this project. Time for some refactoring and a refresh on Flask, a Python (micro) web framework that I sympathize with.
Step 4: How to get the article read time via API
I'm changing the paradigm. Now I want to provide the capability to get an estimation to other applications. The most basic example would be for me to visit some address in my web browser and get a read time. It could also feed a browser extension, a mobile app, etcetera. As long as we can answer HTTP requests asking nicely for our magic algorithm we would be good to go.
That's where Flask comes into the picture.
from flask import Flask
WPM = 220
app = Flask(__name__)
@app.route('/readtime')
def get_read_time():
url = "https://filipesilva.me/blog/12-great-ideas-for-programming-projects-that-people-will-use/"
return str(estimate_read_time(url, WPM))Re-using the existing code, I can very easily deploy on my machine a server that handles a specific HTTP request and estimates the read time of the URL defined. When I open localhost:5000/readtime on my browser I see magic.
Step 5: How to pass parameters to a Flask API
Our API needs to receive from our clients the actual articles they want estimated. To do that we are going to change our GET /readtime endpoint to a POST. This allows us to stay in the good graces of HTTP specifications and what the majority of developers have come to expect.
We will be expecting a JSON payload with a list of URLs (the links for the articles) and a WPM number. The last change from the previous step is how we respond to this request. The jsonify method will convert to JSON a list of pairs comprised of URL and corresponding read time.
from flask import Flask, request, jsonify
WPM = 220
app = Flask(__name__)
@app.route('/readtime', methods=['POST'])
def get_read_time():
request_payload = request.json
urls = request_payload['urls']
wpm = request_payload['wpm']
return jsonify(estimate_read_times(urls, wpm))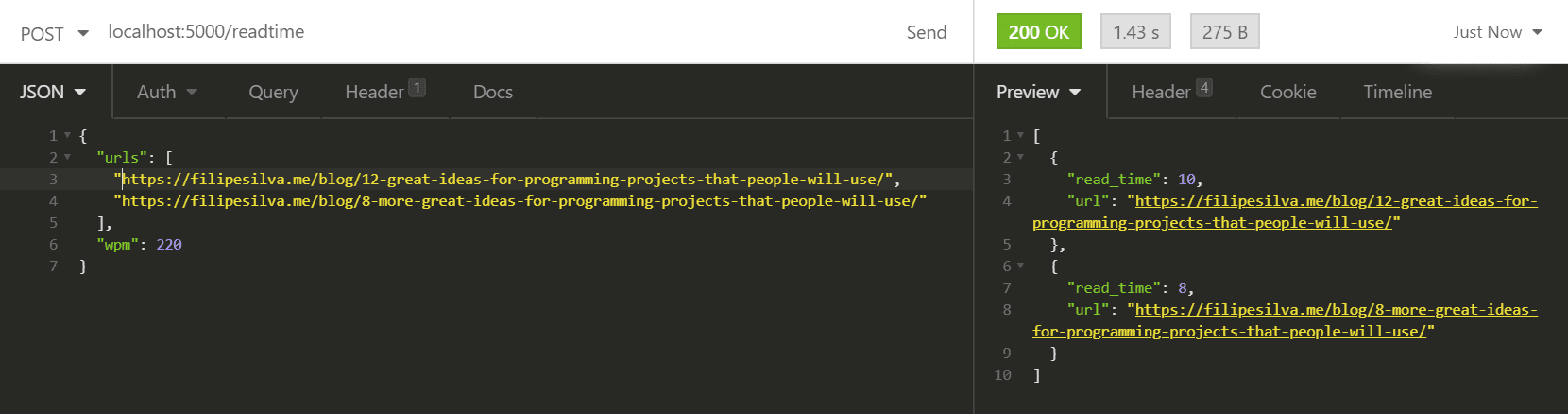
Step 6: How to build a web application with Flask
One of the superpowers of Flask is the ability to render HTML files when you point to certain routes. And not only that, it lets you pass data to those HTML templates so that what you end up seeing in your browser can dynamically change depending on the input.
For this app I envision one page where you will be faced with one or two things:
- a form to input URLs and WPM speed, and
- the result estimation with the read times.
This means that for the same route we should return two different types of content. I decided to keep the POST endpoint to 'ask' for estimations, and included a GET endpoint to serve our landing page with an empty form.
from flask import Flask, request, jsonify, render_template
WPM = 220
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def get_landing_page():
if request.method == 'POST':
url = request.form['url']
wpm = request.form['wpm']
if url:
result = estimate_read_time(url, wpm)
return render_template('landing_page.html', url_estimated=url, estimation=result)
else:
return render_template('landing_page.html')To deliver HTML to our clients we use the render_template() function. Providing an HTML file is fine, but if we want to make it dynamic and take advantage of our jinja2 template engine we can pass named parameters to it and produce magic inside.
Here's our barebones template:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Read time estimation tool</title>
</head>
<body>
<h1>
Read time estimation tool
</h1>
{% if url_estimated %} {% if read_time == 1 %}
<p>The article at {{ url_estimated }} reads in {{ read_time }} minute.</p>
{% elif read_time > 1 %}
<p>The article at {{ url_estimated }} reads in {{ read_time }} minutes.</p>
{% endif %} {% endif %}
<form action="{{ url_for('get_landing_page') }}" method="post">
<label for="url">Link to article:</label>
<input type="url" id="url" name="url" /><br />
<label for="wpm">Words Per Minute:</label>
<input type="number" id="wpm" name="wpm" /><br />
<input type="submit" value="Submit" />
</form>
</body>
</html>
Maybe I even went farther than I wanted. There's no need for a title or a header. The essential parts are the form with fields for URL, WPM, and a submit button. We also have a result section that will only show once we get the estimation our user asked for.
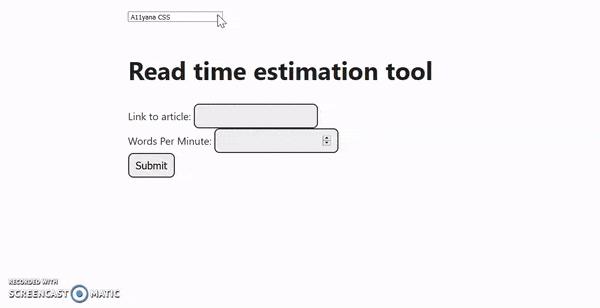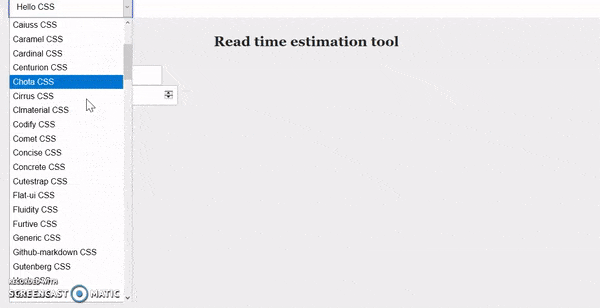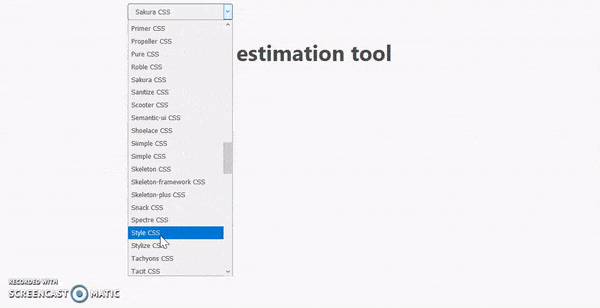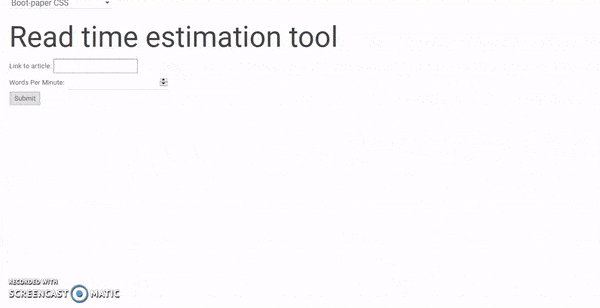
Step 7: How to make a web app a little prettier
The easiest fix we can do for our UI is to use a classless CSS framework. Adding a single line of code in our HTML can have a massive impact. I was in the process of experimenting with some of these frameworks in an old-fashioned way, you know, copying the CDN URL of the CSS class, pasting it in the template, hitting refresh, be mildly surprised, and repeat.
But then I discovered this! Another line of code in our HTML and a drop-down shows up on top of the page allowing us to switch between all of these CSS frameworks.
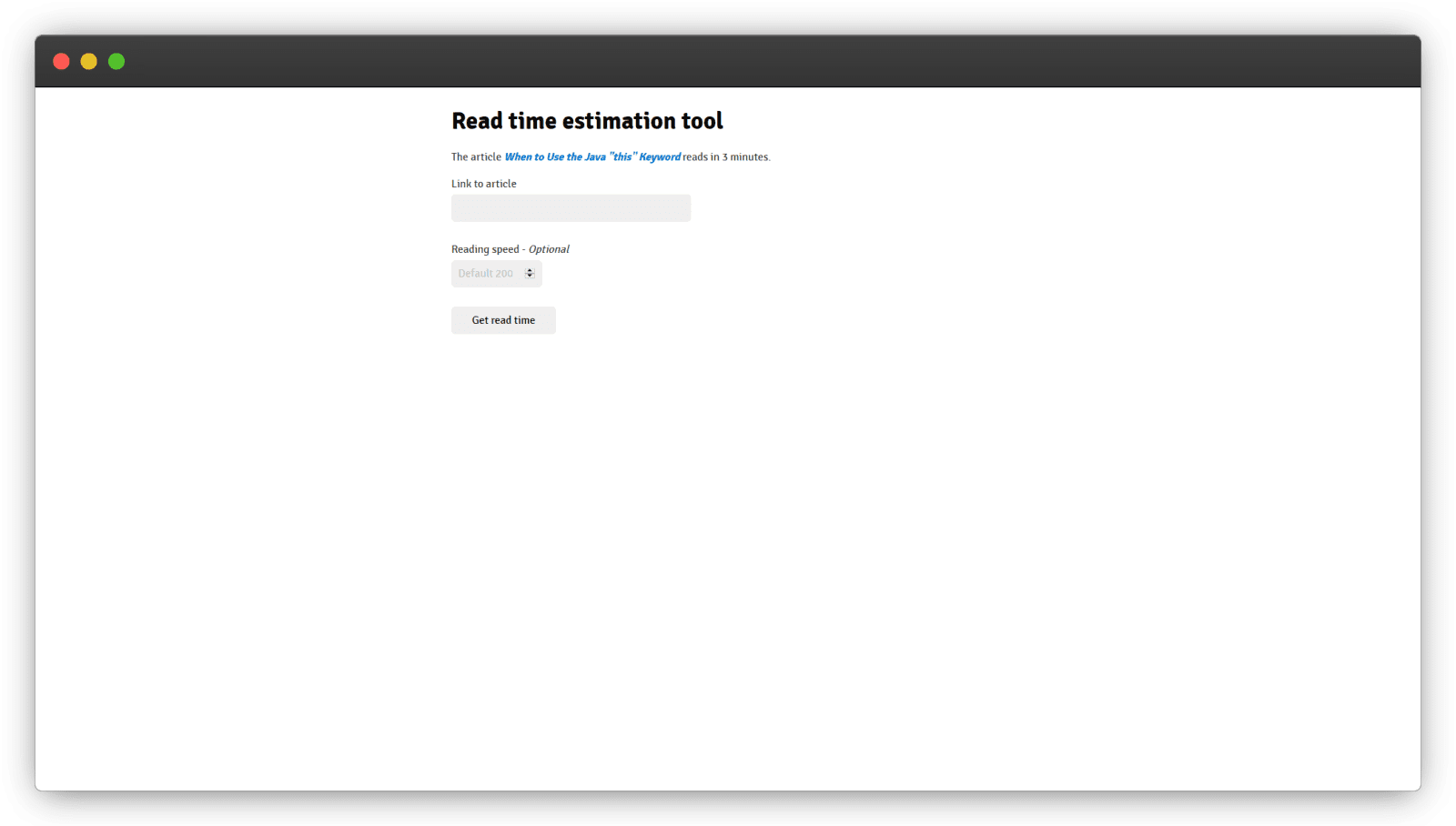
I ended up going with Water.css and applied some more cosmetic details:
- Added the title to the article estimated.
- Change the wording on the uber-generic submit button.
- Shortened length of WPM field.
- Switched the font with an old favorite (Signika).
- Added "optional" tag to WPM field.
Here's proof that super simple details can make the difference.
Step 8: How to make a web app fast(er) and strong(er)
Let's start with the low hanging fruit. Self-host fonts and CSS framework.
I followed this great tutorial for fonts (How To Self-Host Your Web Fonts) and, what can I say, one does not simply download google fonts. Two added tricks about fonts:
font-display: swap;Since I don't mind presenting, briefly, the default font while our chosen one is downloaded.
<link rel="preload" />This will allow the browser to load the fonts even before needed so once they are they're probably ready.
To deal with the CSS framework is much simpler. I just need to download the CSS file and place it in the static folder (yes, if you don't want to do extra legwork, Flask by default will look for every static file in a folder named "static", at the root level) of the app. I also minified the CSS file by 20%.
Another improvement is to Gzip all responses of the app. This is handled by another Python package (Flask-gzip) with one line of code:
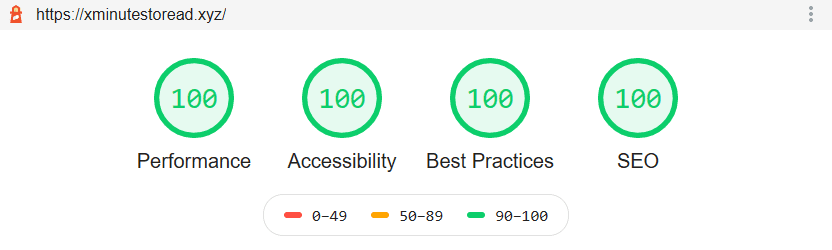
gzip = Gzip(app)And this is how much Google Lighthouse likes our app.
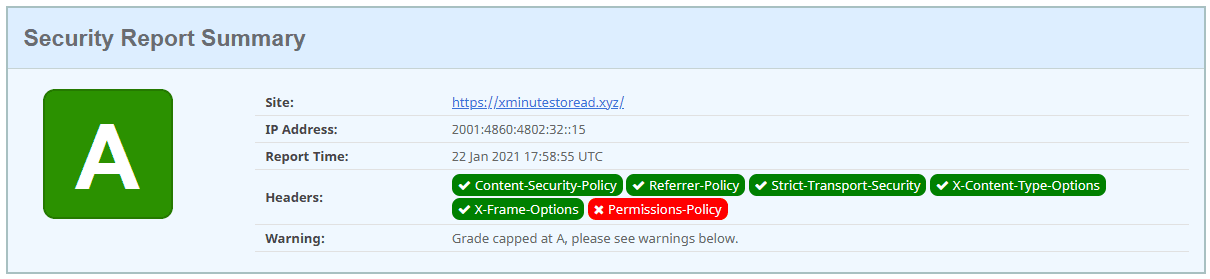
Now in terms of security, we have some headers to provide in our requests.
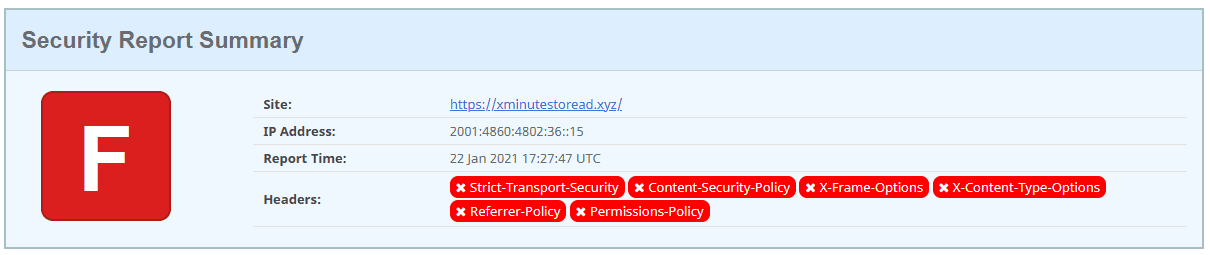
Thanks securityheaders.com. And thanks to another fantastic Flask package, Talisman, we can add default, most recommended, values for each one of these headers. Word of advice (for myself): make an effort to understand what is the purpose of each header and its recommended values. The end result is a header missing that is still a draft and not yet widely supported.
Next Steps
This is for now a basic happy path side project. If everything goes right, it does its job. So the next steps fall into one of two categories: increase resilience, or increase usefulness.
In terms of resilience, my main priorities are adding tests and error handling. These are topics where I can improve both in my Python knowledge in particualr, and expand my software developer skills in general. No one ever became a worse programmer by writing tests and improve error handling in a language they have not so much experience with.
Regarding usefulness, I'm thinking of a browser extension as the most obvious candidate. If I could avoid copy the link to another website and just press a button the improvement would be considerable.
Tiny steps that move things in the right direction are my favorite. Hell, even in the wrong direction, I know it won't be long before I find my way.
If you enjoyed this, there are many others to come.

This is my (almost) weekly newsletter.
You should consider be part of it to stay on top of new articles and other stuff I have yet to figure out. Yup, I'm improvising here.